Let analsysis ALB Logfiles with Athena.
First THX to Rob Witoff https://medium.com/@robwitoff/athena-alb-log-analysis-b874d0958909 for your excellent example.
Next THX is to AWS Support that helped me to figure out some issues.
I tested below CREATE TABLE query with your sample data, and using below schema helped to read your alb logs data successfully:
CREATE EXTERNAL TABLE IF NOT EXISTS logs.web_alb ( type string, time string, elb string, client_ip string, client_port int, target_ip string, target_port int, request_processing_time double, target_processing_time double, response_processing_time double, elb_status_code string, target_status_code string, received_bytes bigint, sent_bytes bigint, request_verb string, request_url string, request_proto string, user_agent string, ssl_cipher string, ssl_protocol string, target_group_arn string, trace_id string) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ( 'serialization.format' = '1','input.regex' = '([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:\-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) ([^ ]*) (- |[^ ]*)\" (\"[^\"]*\") ([A-Z0-9-]+) ([A-Za-z0-9.-]*) ([^ ]*) (.*)' ) LOCATION 's3://<your_bucket>/'Please note that in your sample data, there was no value for year, month and day as provided in the PARTITIONED BY clause in your create table query: PARTITIONED BY(year string, month string, day string) Hence I had to remove the PARTITIONED BY clause from your query. Can you try creating table using above schema and see if that helps in reading alb logs.
- We must activate enable access logs in the properties from ALB.

Enable access logs, choose a name of your bucket and say create this location for me. After this Athena have access to the log files also.
You can generate some data with benchmark tools of the website or you wait some minutes to have some data to analysis.
Then we go to Athena
now it will be a little bit tricky
we must create a db from hand, say add table
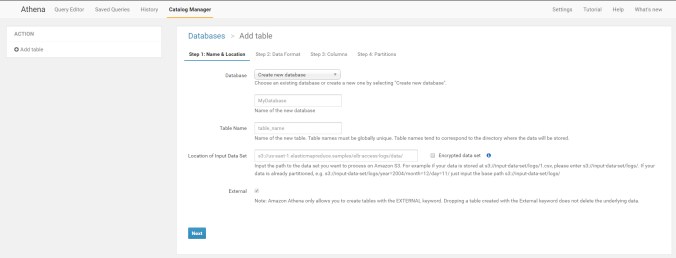
fill it out, database is logs
Table name is web_alb
put your s3 url into it
s3://com.mywebsite.httplog2/AWSLogs/595264310722/elasticloadbalancing/eu-central-1/2017/05/
Say next and choose Apache Web Logs

add one table with name test, we will delete it later
Do nothing here and click, create table
Now we have created a Database with Name logs and a table with Name web_alb

now we just drop the table web_alb
DROP TABLE IF EXISTS web_alb PURGE;

so then we fill in the correct table with all columns that we need
CREATE EXTERNAL TABLE IF NOT EXISTS logs.web_alb ( type string, time string, elb string, client_ip string, client_port int, target_ip string, target_port int, request_processing_time double, target_processing_time double, response_processing_time double, elb_status_code string, target_status_code string, received_bytes bigint, sent_bytes bigint, request_verb string, request_url string, request_proto string, user_agent string, ssl_cipher string, ssl_protocol string, target_group_arn string, trace_id string) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ( 'serialization.format' = '1','input.regex' = '([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:\-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) ([^ ]*) (- |[^ ]*)\" (\"[^\"]*\") ([A-Z0-9-]+) ([A-Za-z0-9.-]*) ([^ ]*) (.*)' ) LOCATION 's3://com.mysite.httplog2/AWSLogs/595264310722/elasticloadbalancing/eu-central-1/2017/05/'
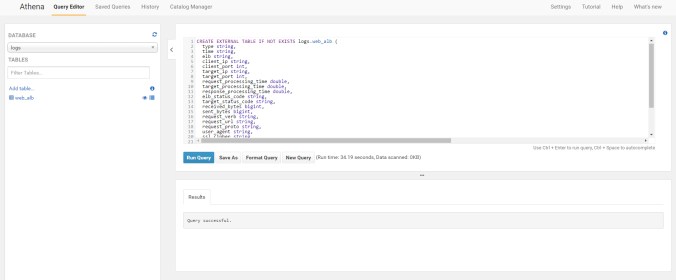
we will fire up our first select
SELECT * FROM logs.web_alb LIMIT 100;
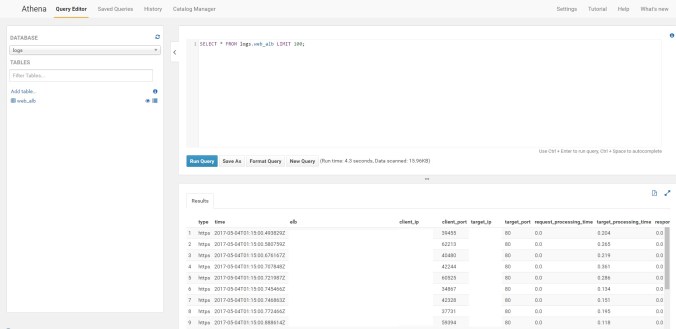
That´s was all
Example for most visitor sorted by most visit with user agent
SELECT user_agent, client_ip, COUNT(*) as count
FROM logs.web_alb
GROUP BY user_agent, client_ip
ORDER BY COUNT(*) DESC
